I haven’t found time to work on the actual RPG lately, but I did have some time to experiment with huffman coding as a way to shorten the number of characters used to represent the image data. It’s doubtful that this improvement will make the Khan Academy CS platform more usable since the uncompressed data will still be large. It’s something that needs to be tested at some point.
Huffman coding is used in jpg image compression. This approach is lossless. Discrete cosine transforms (DCT) and quantization is where the compression becomes lossy and where the most compression improvements will be made.
With image compression, the algorithms work to decrease the number of bytes used to represent the image. In the case of the KA CS platform, images need to be represented as text and then converted to an image. This works fine, but the platform seems to freeze up and occassionally crash when there’s too much code in the editor. It’s not clear whether this is about the actual amount of text in the editor or the amount of processing. The former is a possibility since the code is mostly likely parsed over and over to provide real-time debugging help. This could get slow when the amount of code increases beyond a certain level. Also parsing a string may be faster than an array.
Images in array format can take up a large amount of characters. In the previous post, I described a simple solution that used a color table. This did a good job, but there was definitely more room for improvement, hence this attempt to use huffman coding. Huffman coding was mainly chosen because it aligned with my Computer Vision course.
The first step was to build a histogram of all the values that appeared in each image. Each value is represents a key in the color table. Here were the results of the approximiately 78 values. The most frequent value being “0” at 22%. The zero value stands for the transparent pixel in this case.
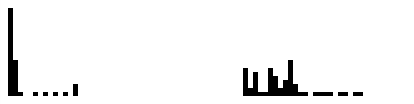
Instead of using “0” and “1” to encode the color values, the digits 0-9 and letters a-z where used. Technically including the capital letters A-Z may have helped too, but that was not included in this attempt.
var codeKeys = [
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9",
"a", "b", "c", "d", "e", "f", "g", "h", "i", "j",
"k", "l", "m", "n", "o", "p", "q", "r", "s", "t",
"u", "v", "w", "x", "y", "z"];
One quirk of using more than two code characters is that the input values must end up with exactly the number of code keys specified. In this case 36. Through some trial and error, the input values must be divisible by X - 1. For instance with 36 codes keys, the next valid number of inputs is 70. After that 105. This is done by simply making sure each step is increased by 35. This is somewhat wasteful since the final table will include unused codes.
The final results showed improvement in the number of characters used to represent an image. One big benefit was being able to represent the values as a string instead of an array. This eliminated a lot of commas. Even with the commas removed from the arrays, the huffman encoded versions still showed some improvement.
| Sprite | Array | Array + No commas | Huffman |
|---|---|---|---|
| Water | 3071 | 2048 | 1024 |
| Cliff | 3071 | 2048 | 1024 |
| Grass | 3071 | 2048 | 1024 |
| Corrina | 3368 | 1833 | 1755 |
| Seth | 3716 | 2181 | 1588 |
The biggest improvement was for the background tiles. This makes sense since each tile uses a small number of colors and were probably processed last when creating the color table. The character sprites on the hand were processed first and contain a lot of transparent pixels which were already set to a value of 0.
The size of the decoder table also needs to be taken into account. A rough attempt to count the number of characters for the table was about 800.
One quick optimization to test out is performing the encoding on each sprite separately. This would make it so a decoder table would need to be included for each sprite. The upside is the decoder tables would be much smaller.
The sample the code used to create the huffman codes for encoding and decoding my image data can be found by following this link here. You’ll need to open the console to see the results.
Also if interested, the source is also posted as a gist.